У меня есть некоторые опасения по поводу этого названия. На самом деле потоковое программирование не по ощущениям похоже на программирование. В большинстве пакетов все, что вам нужно сделать, это построить подобную Lego конструкцию, полученную путем соединения коробок. Ваше мышление должно быть сосредоточено на потоке данных, которые проходят через эти предварительно разработанные блоки, содержащие фактический код.

Потоковое программирование имеет свою историю. Его название неразрывно связано с Дж. Полом Моррисоном, который использовал его в IBM в Канаде, начиная с семидесятых годов. Он написал об этом книгу, которую можно найти или купить в Интернете. Если вам нравятся истории о мэйнфреймах и пакетных заданиях, рекомендую их прочитать.
В книге также изложены принципы, лежащие в основе методологии. Основной из них заключается в том, что информационный пакет (IP) является основной концепцией в программировании на основе потоков, точно так же, как функция в функциональном программировании или инструкция в императивном программировании. В оставшейся части статьи я буду называть IP просто «данными» (входные данные, выходные данные) и, как правило, буду использовать свои собственные термины вместо терминов Моррисона.
Может показаться странным, что слово, используемое для данных, считается центральной опорой методологии программирования. Но именно в этом его отличие от других подходов.
Потоковое программирование — это передача информации из точки A в точку B со всеми промежуточными шагами, которые делают это возможным.
Каждое из полей предназначено для преобразования данных для получения ожидаемого результата. Я буду называть любой из этих блоков подпроцессом, потому что он соответствует более широкому процессу, который также преобразует входные данные в выходные. В конце концов, это черепахи на всем пути вниз.
Задание подпроцесса не заканчивается, когда оно достигает последней инструкции. Он заканчивается, когда нет данных. По этой причине подпроцессы в потоковом программировании ближе к сопрограммам, чем к функциям в традиционном программировании. Порядок выполнения подпроцессов не контролируется программистом; вместо этого его диктуют данные .

Я нарисовал эту картинку, чтобы описать, на что похож подпроцесс. По сути, это ящик с неизвестным содержимым (надеюсь, его имя будет длиннее «А», чтобы дать представление о том, что он делает!), несколько отверстий внутри для ввода и труба торчит сбоку для вывода.
Когда он полностью подключен к входным каналам, подключенным к отверстиям, а выходной канал подключен где-то, подпроцесс готов к потреблению и производству до тех пор, пока поток данных не иссякнет. Это похоже на послушного слугу, выполняющего одну задачу весь день, пока не придет время отпроситься и вернуться домой.
Другое ключевое отличие потокового программирования от традиционного программирования заключается в том, что оно доступно только для чтения. Подпроцесс не может вносить изменения в восходящие данные, поступающие откуда-то еще, поскольку это было бы похоже на возвращение во времени, и это усложнило бы ситуацию — как в фильме «Терминатор».
Несколько блоков подпроцессов могут быть соединены каналами для выполнения конкретной задачи. Эта небольшая сеть каналов и ящиков будет иметь набор входов и набор выходов и преобразовывать данные в соответствии с определенной целью. Мы будем называть его компонентом или составным подпроцессом, и его можно использовать вместо базового подпроцесса.
Компоненты — это основа совместного использования кода на основе потоков. Для любого приложения или ниши есть компоненты, ожидающие сборки, чтобы их можно было использовать повторно.
Причина того, что потоковое программирование особенно подходит для приложений, обновления которых связаны с взаимодействием с пользователем, таких как электронные таблицы, заключается в том, что оно очень хорошо перемещает новые данные в правильном направлении, что означает, например, что формула показывает правильное выходное значение как можно скорее. И я слышал в кругах, связанных с деньгами, чем раньше, тем лучше.
Хотя потоковое программирование очень наглядно, формулы в электронной таблице обычно вводятся в виде текста; однако я не вижу никакого вреда в том, чтобы предлагать оба варианта. Сеть программирования потока легко преобразуется в текстовый рецепт.
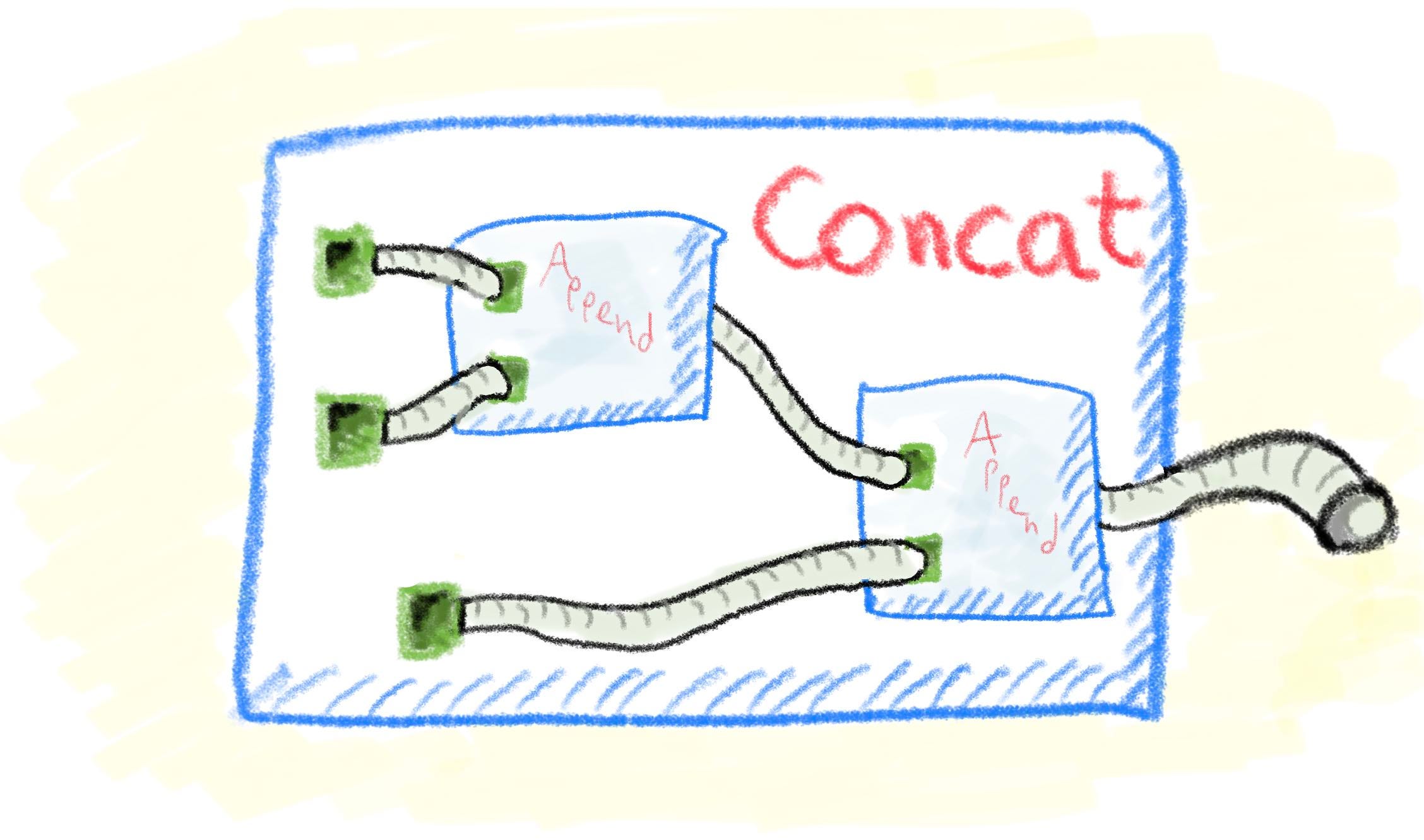
Позвольте мне показать пример. Допустим, я хочу создать компонент Concat, который принимает три входа и дважды использует подпроцесс Append для их объединения. Я мог бы написать это в тексте следующим образом:
Определить Concat как функцию (LeftPart как текст, Glue как текст, RightPart как текст)
- Return(Append (Append (LeftPart, Glue), RightPart))
End Concat
Вы заметили что-нибудь странное?
Что удивительно, так это то, что это выглядит точно так же, как не-поточная программа. Семантика другая, но синтаксис тот же. На самом деле, большинство существующих программ можно хотя бы частично преобразовать в потоковое программирование без изменения кода.
Теперь позвольте мне написать Concat так, как мне действительно хотелось бы написать:
Определить Concat как подпроцесс
- LeftPart как текст = ?
- Glue как текст = ?
- RightPart как текст = ?
- Push(Append(Append(LeftPart, Glue), RightPart))
End Concat
Я заменил Function на Subprocess, а Return на Push, потому что данные передаются в выходной канал. Поскольку LeftPart, Glue и RightPart на самом деле являются именами каналов, которые соединяют входы Concat с входами Append, я поместил их каждый на отдельной строке и использовал вопросительные знаки. для входных отверстий.
Этот подпроцесс будет производить вывод до тех пор, пока он получает входные данные, и если выходной канал к чему-то подключен, результат появится там.
Вот и все сегодняшнее введение в потоковое программирование, надеюсь, вам понравилось!
Как всегда, пожалуйста, задавайте свои вопросы в разделе комментариев.